Poster
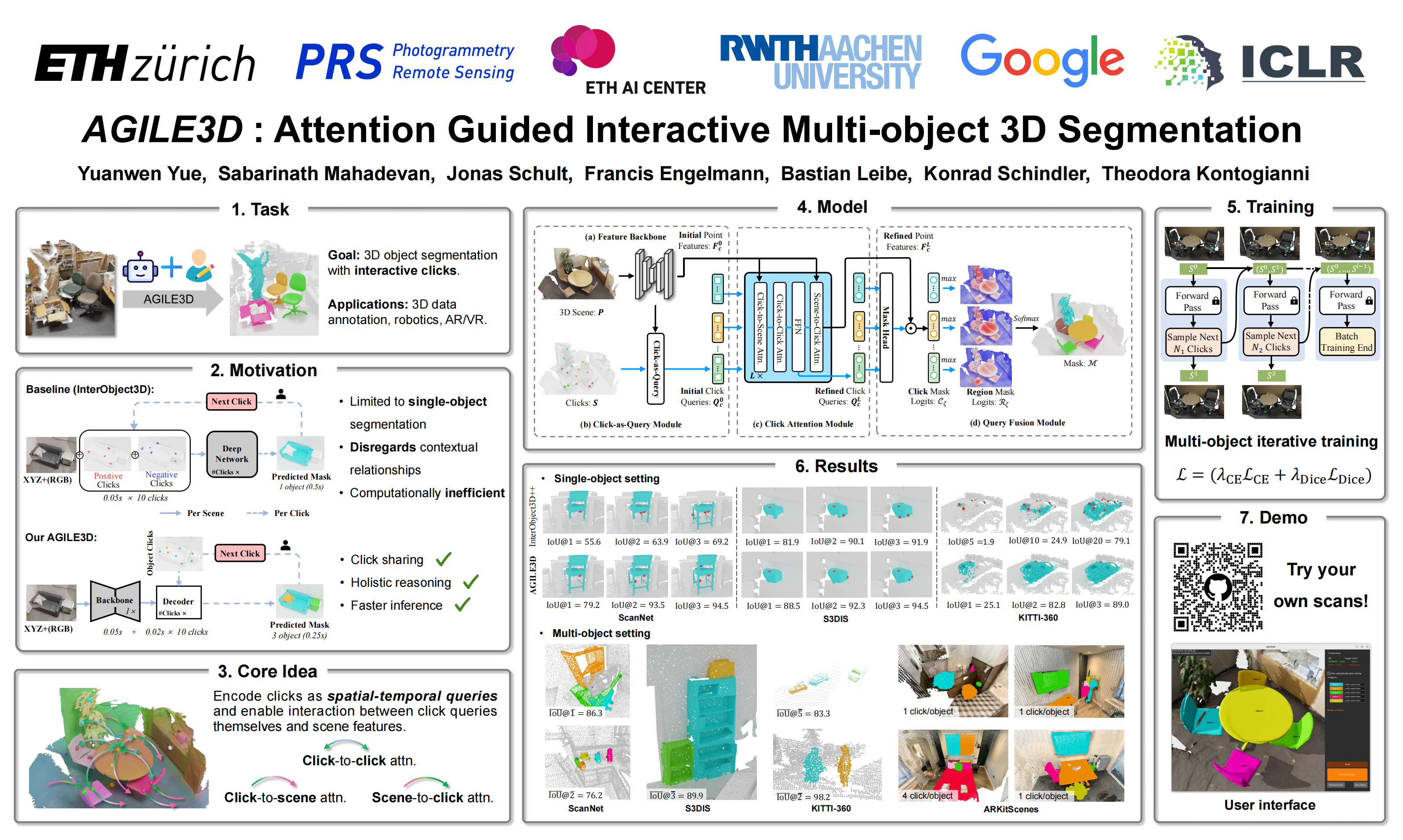
During interactive segmentation, a model and a user work together to delineate objects of interest in a 3D point cloud. In an iterative process, the model assigns each data point to an object (or the background), while the user corrects errors in the resulting segmentation and feeds them back into the model. The current best practice formulates the problem as binary classification and segments objects one at a time. The model expects the user to provide positive clicks to indicate regions wrongly assigned to the background and negative clicks on regions wrongly assigned to the object. Sequentially visiting objects is wasteful since it disregards synergies between objects: a positive click for a given object can, by definition, serve as a negative click for nearby objects. Moreover, a direct competition between adjacent objects can speed up the identification of their common boundary. We introduce AGILE3D, an efficient, attention-based model that (1) supports simultaneous segmentation of multiple 3D objects, (2) yields more accurate segmentation masks with fewer user clicks, and (3) offers faster inference. Our core idea is to encode user clicks as spatial-temporal queries and enable explicit interactions between click queries as well as between them and the 3D scene through a click attention module. Every time new clicks are added, we only need to run a lightweight decoder that produces updated segmentation masks. In experiments with four different 3D point cloud datasets, AGILE3D sets a new state-of-the-art. Moreover, we also verify its practicality in real-world setups with real user studies.
@inproceedings{yue2023agile3d,
title = {{AGILE3D: Attention Guided Interactive Multi-object 3D Segmentation}},
author = {Yue, Yuanwen and Mahadevan, Sabarinath and Schult, Jonas and Engelmann, Francis and Leibe, Bastian and Schindler, Konrad and Kontogianni, Theodora},
booktitle = {International Conference on Learning Representations (ICLR)},
year = {2024}
}